ankiデッキの作成メモ
メモ
- 作業ディレクトリ:
- D:\prj\Anki\Parser
DRMを解除する
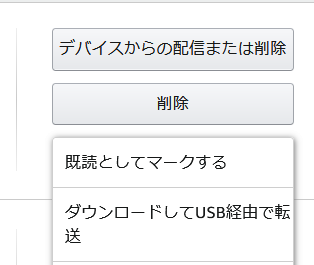
Kindle書籍のazw3を取得する
Amazonウェブサイトからコンテンツの管理 > その他アクション >ダウンロードしてUSB経由で転送
DRMを解除する
使用環境: Calibre6.13, DeDRM_tools10.0.3
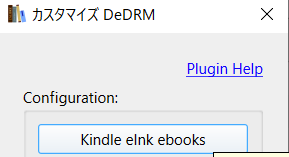
Calibreの環境設定 > プラグインからダウンロードしたzipファイルを指定してインストール

プラグイン > DeDRM をダブルクリック > Kindle eInk ebooks をクリックして Kindle の尻を入力する。
Calibre の本を追加から azw3 を指定してインポートする。
Calibre のビューワでインポートした Kindle 書籍が見れたら DRM 解除は成功している。
テキストデータを取得する
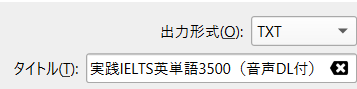
Calibre > 本の変換 > 出力形式に TXT を指定してコンバートする。
以上
IELTS 3500 旧版テキストフォーマット
- ID
- 単語
- 発音
- □ 例文
- * * *
- 品詞1 意味
- 品詞2 意味
- 類語1, 類語2,
- □ 例文意味
その他
- 単語セクション開始終了
- 開始: 「^[0-9]+\n」で引っかけられる
- 末尾:
- 3500語目のみ 2 回目の「□」の登場
- それ以外は次の「番号」まで。但し、下記 early out が必要。
- 1. 「^Column\n」が出現したら early out.
- 2. 「^重要語レベル」が出現したら early out.
1. が先に出現するので順番に注意。 - 1-1000のみ
- 単語配下の要素
- ID :
- 単語 : 必ず「ID\n」から始まる
- 発音 : 必ず [ で始まる(基本語除く)
- □ 例文 : 必ず 1 単語 1 例文(基本語除く)。発音から \n\n\n で始まる
- * * *
- 品詞1 意味 : “名 意味”
- 品詞2 意味 : 品詞1 に空行を挟んで “名 意味”
- 類語1, 類語2,
- □ 例文意味 : 必ず 1 単語 1 例文(基本語除く)
- ****
- タグ
- 基本語1000
- 重要語レベル1
- 重要語レベル2
- 重要語レベル3
- 重要語レベル4
Ankiのデータ構造
csv のデータ構造
csv の列とフィールドを指定できる。今回は下記の csv を出力することにする。
“IELTS_Word_3500_1998″,”orientate”,”[ɔ́ːriəntèɪt]”,”The accounting course is orientated towards beginners.”,”[他] を(〜に)向ける;を適応させる<br>[名]オリエンテート”,”direct; adapt, familiarise”,”その会計学のコースは初心者向けである。”,”[sound:(be) pressed for time.mp3]”,”重要語レベル1″
NOTE
- IDがノート内でユニークになるようにする
- , を含む場合があるのでセルは “” で囲む
音声の命名規則
[sound:BookTitle_word.mp3]
[sound:BookTitle_word_example.mp3]
音声分割
他の単語帳でもやるだろうしスクリプトを書いておく。
Audacity なんかを試したけど mp3splt をコマンドラインで使うのが楽。ffmpeg を直接叩く場合は複数コマンドになるのでダルい。
mp3splt 分割設定
- mp3splt で -60db のスレッショルド指定でうまくいく
- コマンド例:
“/cygdrive/c/Program Files (x86)/mp3splt/mp3splt.exe” -s 3001-3020.mp3 -p th=-60
mp3splt は分割パラメータがちゃんと通っていない気がする。分割数が ffmpeg や Audacity と比べると著しく多かったりした。
結局、IELTS3500の音声には下記の問題があり完全自動は難しい。
- 単語間の無音は1.8-2.0secが基本だが、数箇所1.0secの空白が紛れている
- 因みに単語と例文の切れ目は1.0secが基本で例外はないように見える
- 単語の発音が 2 パターン収録されているものがある(ソースの欠陥ではないが、1単語に対する音声数が可変するので辛い)
なので Audacity を使って下記のワークフローをとった。
- Audacityの「解析 > サウンドから自動ラベル付け」をやりやすくするためにレベル毎に全 mp3 を連結して 1 ファイルにする
- Audacity に連結した mp3 を食わせて自動ラベル付けをする。設定は、RMS -80dBで無音判定、区間は1.8sec。これで各レベル500以下に分割される。
- 数が足りない場合は、単語間の空白が 1.0sec になっている。ラベルを眺めていくと明らかに長いラベルがあるので手動で分割して再度自動ラベル付けを行う。
これで各単語毎の音声のチャンクが作れる。必要に応じて単語例文は無音区間0.8sec位で分割すればよい。
音声データのリネーム
メモ
- 単語と例文を分割
- “.mp3_” を “_” に置換
- 末尾 _0 _2 _4 となっているのを _0 _1 _2 に置換。
- _1 は他の発音方法なので _0 と _2 を採用すればよい。
- – を削除する
- TODO:
- DONE: ↓のリネーム
D:\prj\Anki\IELTS_konin\SplittedSound\j5_3001-3500
ielts_3500_j5_1.mp3
1001ファイルあるのでどこか特定する- 250 -> scuffle 500 が例文になっている。
- 520 例文
- 543 overhang が発音二つある。先頭アクセントは一般的でないので削除する。
-> 544 から後の番号は -1 する。 - 全て 3000 足す。
- 250 -> scuffle 500 が例文になっている。
- DONE: ↓のリネーム
D:\prj\Anki\IELTS_konin\SplittedSound\k_1-1000
サウンド01.mp3 - DONE: “.mp3_” を “_” にリネーム
- DONE: 1単語3音声のものを抄出して削除
- DONE: サフィックスが _0 _2 となっているのを _0 _1 に変更する
- DONE: ↓のリネーム
mp3をankiにインストールする
- 下記に配置する。ディレクトリを掘ったら駄目。
C:\Users\WindowsSeven\AppData\Roaming\Anki2\ユーザー 1\collection.media
cf. anki reference
ankiのノートタイプとデッキとは

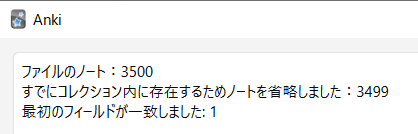
- 最初のフィールドを unique id にしとかないと再インポート時に単語の重複検査に滅茶苦茶時間がかかるようになる。ユニークにしていると下記のように1単語だけ更新があったらそれ以外の更新が省略される。
ankiでタグをうまく使う
- タグで覚える単語をフィルタリングできるのか?
PCのデッキをiphoneと共有する
アカウントを作れば「同期」ボタンで同期できる。
ankiの基本事項・設定方法
- 学習ステップの概念
- 新規カードは Again, Hard, Good, Easy の学習ステップを経て Review Card となる。
- Review Card
- ここでも Again~Easy のステップを選択してレベルに応じて出題間隔が決まる。
- Suspend Card 休止カード
- 手動で休止を解除するまでは二度と表示されない。市販の単語帳を覚える場合、知っている単語は休止カードにして出題されないようにする。
- フィルターデッキ
- ankiのコンセプトとして「通常学習により無駄なく効率的に暗記ができる」というのがまず前提
- フィルターデッキでは、通常学習に加えて、テストなどがあるから復習をしておきたい等の用途で使用する
コメントを残す